Cześć,
Tu Kuba - fajnie, że czytasz 🙂 mamy dzisiaj sporo do omówienia:
Do dzieła, miłej lektury 👍
Zero spamu. Możesz wypisać się w każdej chwili.
Poznaj naszą politykę prywatności.
Są takie rzeczy o których z ChatemGPT nie rozmawiam... nie mogę, nie chcę, albo się wstydzę 😉 pewnie to znasz. Z ratunkiem przychodzą tutaj modele open source, które w kilka minut możesz odpalić na swoim komputerze.
Dlaczego warto?
A dodatkowo (bo są wśród Was ludzie biznesu 🤑) - jeżeli nauczysz się komercjalizować tą umiejętność - można na tym dobrze zarobić. Coraz więcej soloprzedsiębiorców czy agencji butikowych robi niemałe pieniądze 💰 na dostarczaniu lokalnych modeli AI dla swoich klientów.
Jakie są minusy?
Podstawowy minus jest taki, że jakość modeli które można uruchomić na domowym sprzęcie jest... umiarkowana. Jeżeli ChatGPT o3 potraktujemy jak dobrze opłacanego Senior Konsultanta z McKinsey, to lokalny LLM jest takim nieco mniej ogarniętym juniorem świeżo po studiach 😉. Wciąż może być przydatny ale nie oczekuj cudów.
Natomiast jeśli uznasz, że ma to sens, może zaczniesz (tak jak ja) interesować się poleasingowymi serwerami z 1TB pamięci RAM na którym można odpalić najnowszego Deepseek-r1:671b 💪. Z takim sprzętem można być bardzo blisko możliwości komercyjnych modeli (pod względem jakości - na wydajność, niestety, nie ma co liczyć).
O co chodzi z tym "b"?
Jest cała masa darmowych (open-source) modeli które możesz pobrać na swój komputer i korzystać z nich lokalnie. Dzisiaj spróbujemy uruchomić model Deepseek-r1:8b którego aktualizacja wyszła (w momencie pisania tego maila) dosłownie kilka godzin temu.
8b to ilość parametrów w modelu → b jak BILION, czyli 8 000 000 000 000. I to jest model wagi piórkowej. Rozmiar takiego modelu na dysku to ok. 5.3GB a to oznacza, że jeśli chcesz go odpalić na własnym sprzęcie musisz mieć nieco ponad 5GB wolnej pamięci RAM. Jeżeli masz dedykowaną kartę graficzną z pamięcią VRAM to jeszcze lepiej, poniżej porównanie przepustowości:
Są zastosowania w których nic poza VRAM nie ma sensu, natomiast do wielu zadań i automatyzacji rodzaj pamięci może nie mieć wielkiego znaczenia. Opóźnienie rzędu minuty, czy dwóch, w klasyfikacji jednego e-maila jest raczej akceptowalne. Disclaimer - jeżeli chcesz odpalić lokalnie model na VRAM to ten poradnik Ci w tym nie pomoże.
Jest wiele sposobów żeby lokalnie uruchamiać modele LLM, ja lubię korzystać z Ollama. To taki Docker-dla-LLM'ów.
Co warto wiedzieć o Ollama:
Jak zacząć?
Sam proces instalacji jest bardzo prosty, a instalator nie pyta nas w zasadzie o nic...
Po instalacji Ollama uruchamia się automatycznie "w tle". A więc - nie zobaczysz żadnego okienka ani interfejsu programu, nie dowiesz się nawet, że instalacja przebiegła pomyślnie.
Aby pracować z Ollama musisz, tak jak wspomniałem, korzystać z interfejsu linii poleceń (CLI). Dla mnie jest to standardowy Windows Command Prompt:
Natomiast można oczywiście z PowerShell czy Terminalem na macOS. Jak masz Linuxa to tłumaczyć nie muszę 🤐.
Jeśli u Ciebie Ollama nie wystartowała z automatu możesz to zrobisz to komendą:
ollama serve
Jeżeli, tak jak wspomniałem, Ollama już działała w tle, dostaniesz bardzo jasny i klarowny komunikat "Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted." 😉
Teraz jesteśmy gotowi na pobranie i uruchomienie Deepseek'a - wpisz
ollama run deepseek-r1:8b
i... poczekaj chwilę, Ollama musi pobrać model 8b (a więc nieco ponad 5GB danych) na Twój komputer.

No i można zaczynać... kiedy model się ściągnie Ollama da nam znać i uruchomi natychmiast model. Zobacz jak wyglądał przebieg rozumowania Deepseek'a dla prostej wiadomości - "hello":
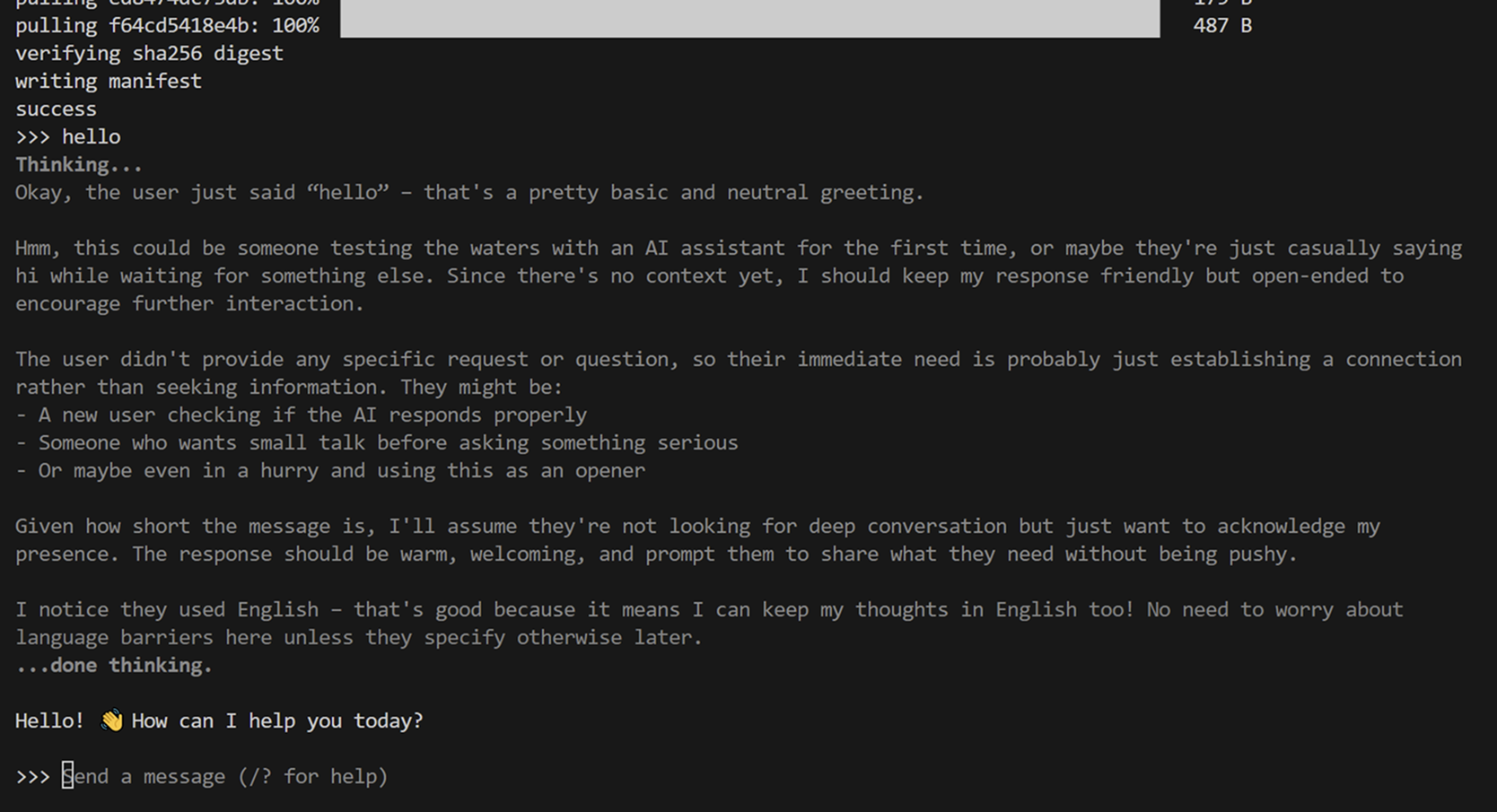
Nie wiem jak Ty, ale ja jestem pod wrażeniem... 😂 tyle "myślenia" aby dojść do wniosku, że najlepsza odpowiedź to "Hello 👋 How can I help you today?". Jako introwertyk - rezonuję z tym 😉.
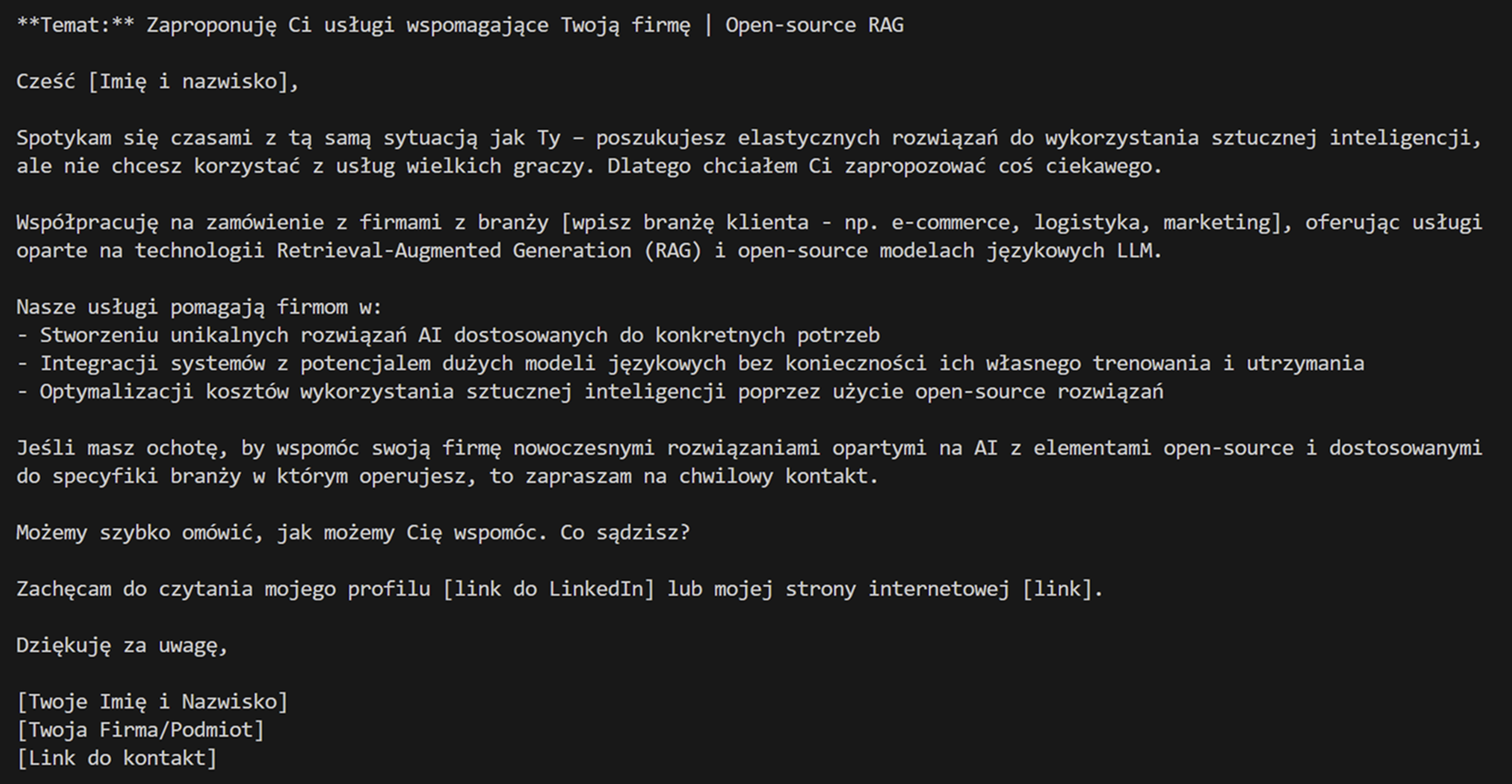
Dla nieco trudniejszego zapytania (np. w języku polskim, dotyczącego napisania cold-mail'a B2B) wydajność tego modelu na moim komputerze wyniosła 5 tokenów na sekundę. Token to, w skrócie, całe słowo, jego cześć lub np. znak interpunkcyjny (przyjmuje się często, że 1 token to 0.75 słowa).
Poniżej wspomniany mail 👇, raczej nie będzie "żarło" (chociaż zdarzało się, że dostawałem gorsze) ale jak na coś zrobionego od A do Z przez lokalny model - jest całkiem nieźle.
Oczywiście, tak jak wspomniałem - w tle działa gotowe REST API, więc można szybko zapomnieć o pracy z CLI jak jaskiniowiec i połączyć się z modelem przez np. Langflow.
Podsumowując: to oczywiście dopiero początek zabawy w lokalne LLMy, ale mam nadzieję że pobudziłem Twój apetyt. Daj proszę znać w odpowiedzi na tego maila czy podjęłaś/podjąłeś zadanie. Jeżeli chcesz w kolejnym odcinku podejść do tematu wykorzystania lokalnych modeli koniecznie napisz.
1️⃣
Kolekcja Workflow n8n: o n8n już dzisiaj wspominałem, ale jeśli jeszcze nie znasz tego narzędzia to warto się zainteresować. Nie chodzi tu nawet o tworzenie ultra przydatnych automatyzacji - stwórz cokolwiek, wrzuć na LinkedIna screenshot'a i napisz, że podzielisz się tą fantastyczną automatyzacją za lajka, komentarz, follow, zdjęcie na maila i 10 zł blikiem 😊.
A jak chcesz drogę na skróty sprawdź https://n8nworkflows.xyz/ - znajdziesz tam ponad 2300 gotowych do wykorzystania workflow. Są gwiazdeczki, kategorie, opisy - nic, tylko przeglądać i korzystać.
s. o robieniu zasięgów na publikacji swoich workflow n8n przeczytałem niedawno... właśnie na LinkedIn, ale za choinkę nie mogę znaleźć posta aby wspomnieć tutaj, jak nakazuje obyczaj, jego autorkę/autora.
2️⃣
Akademia OpenAI: O OpenAI dzisiaj jeszcze chyba nie pisałem... W każdym razie twórcy ChataGPT uruchomili darmową akademię, w której znajdziesz bardzo dużo soczystych porad i przewodników -> https://academy.openai.com/. Jeżeli, tak jak ja, masz wrażenie, że korzystasz z 3% możliwości swojej subskrypcji za 20$ - wrzuć sobie w kalendarz godzinę albo dwie na Akademię i popracuj nad swoim warsztatem.
3️⃣
Excape hatch: czyli "wyjście ewakuacyjne" w rozmowie z AI może znacznie podnieść jakość konwersacji (zwłaszcza - uniknąć tzw. halucynacji). Posłuchaj krótkiej wypowiedzi na X na ten temat tutaj.
TL;DR? warto w promptach zaznaczyć "Jeśli nie masz wystarczających informacji aby odpowiedzieć na pytanie, zatrzymaj się i dopytaj.". Dodatkowo, w drugiej części filmiku, znajdziesz świetny use case do bardziej zaawansowanych zastosować (automatyzację, wykorzystanie AI w aplikacjach) - moim zdaniem ogień 🔥.

Dzisiaj krótka rekomendacja. The 1-Page Marketing Plan: Get new customers, make more money and stand out from the crowd. Autor: Allan Dib. Polecam w oryginalnej wersji językowej na audible.co.uk.
Jeśli marketing kojarzy Ci się z chaosem, lansem i przepalaniem budżetu - ta książka to antidotum. Allan Dib proponuje prosty framework: jeden arkusz, dziewięć pól, które prowadzą Cię od "nie znają mnie" do "kupują ode mnie i polecają innym".
✔️ Co mi się spodobało?
Zero lania wody. Konkretne pytania, które zmuszają do refleksji: kogo dokładnie chcesz przyciągnąć, co masz im do zaoferowania i jak to zrobić bez wielkiego zespołu.
🧠 Dla kogo?
Dla każdego, kto buduje swój produkt, usługę czy markę - solo czy w zespole. Nawet jeśli nie jesteś „marketerem”, ta książka pomoże Ci zrozumieć, co działa.
Pytacie mnie często w komentarzach od jak dawna.... Nie no, dobra, o nic mnie nie pytacie. Nie będę przed Tobą ukrywał prawdy -najtrwalsze związki buduje się przecież na zaufaniu i transparentności 😎. Czytasz właśnie pierwszy odcinek newslettera Ogarniam Technologię.
Dotrze on do nieco ponad 40 osób. Mam nadzieję, że każdego tygodnia będę tutaj mógł podzielić się coraz ciekawszymi liczbami i statystykami.
Na dzisiaj zakończę krótko - dziękuję że się zapisałaś/zapisałeś. Do usłyszenia w przyszły poniedziałek 🙂.
Udanego tygodnia!
Pozdrawiam
Kuba Jaszczu

Zero spamu. Możesz wypisać się w każdej chwili.
Poznaj naszą politykę prywatności.