Cześć,
Z tej strony Kuba. Dzisiaj wracamy do tematu skutecznego wykorzystania sztucznej inteligencji. Jak zawsze jestem super ciekawy, czy to, co tu dzisiaj znajdziesz, jest dla Ciebie do wykorzystania. Będę bardzo wdzięczny za każdy komentarz, a jeżeli rzeczywiście uznasz to za wartościowy materiał — podziel się newsletterem z chociaż jedną osobą, która również może na nim skorzystać 🙏. Wystarczy, że prześlesz ten link 👉 ogarniam.tech. Dziękuję!
A teraz do rzeczy, co znajdziesz w dzisiejszym odcinku:
Zaczynamy 🙂
Zero spamu. Możesz wypisać się w każdej chwili.
Poznaj naszą politykę prywatności.
Nie wiem, z jakiego “AI” korzystasz, ale jest spora szansa, że nie wykorzystujesz pełni jego potencjału. Modele językowe odpowiedzą nam na każde zapytanie, niezależnie od tego, jak dobrze je przygotuje. W rezultacie, ponieważ odpowiedź zazwyczaj jest „OK” łatwo popaść w rutynę i przyzwyczaić się do umiarkowanej jakości.
Musisz jednak wiedzieć, że z AI można wyciągnąć znacznie, znacznie więcej. Jeżeli nie chcesz bawić się w zaawansowane techniki — największy zwrot z inwestycji przyniesie Ci właśnie dobre opanowanie promptu. I, dla jasności, pewnie nie przedstawię tutaj jakichś niesamowitych „hacków”, czy sztuczek. Chciałbym raczej dać Ci systemowe podejście, które można zastosować do każdej rozmowy czy zapytania. Absolutne podstawy, których nie wykonuje 90% użytkowników modeli LLM. Jeżeli je opanujesz, będziesz w czołówce.
Prompt to treść, którą wpisujesz do swojego modelu AI – jedno zdanie, pytanie albo rozbudowana instrukcja z kontekstem i wymaganiami. To dokładnie mówi modelowi, co ma zrobić (np. „Stwórz listę 5 pomysłów na kampanię”, „Wyjaśnij fotosyntezę prostym językiem”).
Na starcie — warto sobie przypomnieć, jak w zasadzie działają modele językowe. Są to maszyny statystyczne, których jedynym zadaniem jest przewidywanie kolejnego tokenu. Nie rozumie kontekstu tak jak człowiek — po prostu zamienia prompt na tokeny a tokeny na liczby, które później „przepuszcza” przez warstwy transformera (Transformer to ta literka „T” w GPT) i zwraca rozkład prawdopodobieństwa kolejnych tokenów.
Trochę jak Ty, kiedy czytając ten tekst, zaczynasz powoli domyślać się, jakie będzie ostatnie słowo tego …………. zdania 😉.
Następnie – zgodnie z ustalonymi parametrami generowania – wybiera ten o najwyższej (lub wystarczająco wysokiej) szansie i dokleja go do wypowiedzi, po czym cały proces powtarza się dla następnego tokenu.
Token to kilka znaków lub całe słowo. Dla języka angielskiego przyjmuje się, że 1 token = 0,75 słowa, i dla większości modeli to właśnie język angielski jest najbardziej efektywny. W języku polskim można przyjąć, że token to ~0,5 słowa, bo same słowa są dłuższe, a do tego dochodzą dodatkowe znaki diakrytyczne. To tylko na marginesie, ale jeżeli pracujesz z automatyzacjami i zależy Ci na optymalizacji wykorzystania dostępnych w subskrypcji limitów — warto stosować język angielski dla zadań „wewnętrznych” (np. agent-recenzent oceniający przydatność artykułu dla czytelników newslettera) a dopiero na koniec (np. ostatni agent zajmujący się formatowaniem tekstu, pisaniem postu na social media) prosić o odpowiedź w języku polskim.
Może o tym nie wiesz, ale poza Twoim zapytaniem, model bierze także pod uwagę:
Warto dodać, że modele w tym wszystkim nie są nieomylne. Zdarza się im generować, z pełnym przekonaniem, odpowiedzi powierzchownie prawidłowe i wiarygodne, ale faktycznie — błędne i nielogiczne. Potocznie nazywamy to halucynacjami.

Halucynacje nasilają się przy zbyt kreatywnych ustawieniach (wysokie temperature), nieprecyzyjnych promptach albo gdy zadanie wymaga wiedzy spoza czasu treningu modelu. Skuteczne prompty pozwalają znacząco ograniczyć ich występowanie. Jak ograniczyć halucynacje:
Prompt engineering to proces projektowania skutecznych promptów, które pozwalają uzyskać od modeli językowych odpowiedzi precyzyjne, spójne i dopasowane do naszego use case’u. W zależności od zadania można stosować różne techniki – od nadania modelowi konkretnej roli („Jesteś analitykiem danych…”), przez określenie formatu odpowiedzi, aż po dodanie przykładowych danych wejściowych. Te zabiegi potrafią znacząco podnieść jakość odpowiedzi.
Kluczowe jest podejście iteracyjne: warto testować różne warianty, porównywać wyniki, dopracowywać prompty krok po kroku. Eksperymentując i ucząc się na wynikach, można wypracować własny warsztat – zestaw sprawdzonych szablonów, które przyspieszają pracę i gwarantują spójność w kolejnych zadaniach. Polecam Ci, abyś zaczęła/zaczął pracować nad takimi szablonami, zwłaszcza dla najczęściej powtarzanych zadań.
To szczególnie ważne w kontekście automatyzacji i tworzenia agentów AI. W takich scenariuszach nadzór człowieka nad każdym wywołaniem modelu jest minimalny, dlatego dobrze zaprojektowany prompt staje się kluczowym elementem niezawodności całego procesu. Solidne prompty działają jak instrukcja obsługi – im lepsza, tym mniejsze ryzyko błędów i tym większa skuteczność systemu.
Oprócz dobrze zaprojektowanego promptu warto tworzyć dodatkowe dokumenty, które mogą być załączane do kolejnych wywołań modelu. Przykład? Sam stworzyłem opis profilu czytelnika newslettera – gdzie tak precyzyjnie, jak potrafię, opisałem: kim jest, czego szuka, jakim mówi językiem, jakie ma problemy i wyzwania, jakie ma kompetencje, czego należy unikać itd… Mój dokument jest dosyć długi i wracam do niego często, aktualizując go i zmieniając priorytety.
Dzięki takim załącznikom można zapewnić spójność odpowiedzi w kolejnych rozmowach, bez konieczności powtarzania tego samego kontekstu w każdym promptcie.
Możesz go stworzyć np. jako plik tekstowy (.txt), chociaż, jeżeli chcesz nadać informacjom wagi a całemu dokumentowi struktury, polecam format Markdown. Jest to prosty, przejrzysty i łatwy do nauki format, który jest bardzo czytelny — zarówno dla nas, jak i dla AI. Plik w formacie Markdown to zwykły plik tekstowy, wzbogacony o kilka „markerów”, które nadają mu struktury. Polecam Ci ekspresowe wprowadzenie do formatu Markdown, w postaci interaktywnego tutoriala, dostępne w języku polskim. Obiecuję, że opanujesz podstawy kilka minut, a do swojego warsztatu będziesz mogła/mógł dodać kolejną, cenną umiejętność.
Odnośnie do automatyzacji — baza wiedzy w postaci dokumentu Markdown może być tutaj ograniczeniem albo kosztownym elementem procesu (ze względu na ilość tokenów konsumowanych na wejściu). Dopóki nie odbijesz się od ściany kontekstu lub nie zaczniesz przekraczać budżetu tokenów — nie ma problemu. Później — wchodzisz w RAG lub inne, zaawansowane metody…
Oooffff… miało być krótkie wprowadzenie, wyszło jak zawsze 😄.
Wierzę, że te podstawy okażą się dla Ciebie przydatne, a teraz — przechodzimy do konkretnych porad i przykładów skutecznych promptów. Szablon, który chciałbym Ci zaproponować, to sprawdzony i opisany w wielu przewodnikach kwartet:
Taką strukturę proponuje m.in. Google, w swoim opracowaniu Gemini for Google Workspace / Prompting Guide 101. Warto zaznaczyć, że porady dotyczące promptów, które znajdziemy w dokumentach przygotowanych przez rozmaite laby, dla swoich modeli LLM (np. Właśnie Google, Anthropic, OpenAI, Meta, X, etc..) są zazwyczaj uniwersalne i zadziałają z każdym modelem językowym.

Google we wspomnianym opracowaniu podaje, że optymalne rezultaty zaczynamy uzyskiwać w przypadku promptów o długości 21 słów. Większość promptów ma tymczasem poniżej 9 słów. Inna cenna obserwacja — promptowanie, to umiejętność, której można się nauczyć. Nie musisz być prompt engineerem, by skutecznie wykorzystywać generatywne AI.
W tym opisie podam Ci kilka przykładów wykorzystujących powyższą strukturę, bazujących właśnie na opracowaniu od Google.
Zastosowanie tej struktury do przykładowego zadania może wyglądać następująco:
Mamy tu więc:
Jeżeli chcesz zobaczyć podobne rozbicie dla kolejnych promptów, odsyłam do opracowania Google / Prompting Guide 101.
Komentarz: Do takiego promptu załączamy właśnie wspomniany dokument doprecyzowujący kontekst, np. W formacie Markdown. Rezultat zapytania z mojej perspektywy idealny nie jest, ale dużo bardziej trafny niż odpowiedź na zapytanie „Napisz artykuł na stronę o modelach językowych w social media”.
Wiem, że są wśród Was wykładowcy akademiccy, nauczyciele i pracownicy administracji. Dobry prompt może Wam znacznie ułatwić prace nad koncepcją i organizacją wydarzeń. Poniżej przykładowa konwersacja, która pokaże Wam, jak to zrobić (na bazie jednego z przykładów z opracowania Google).
To zapytanie zawiera wszystko, co potrzeba, aby rozpocząć proces planowania. Jeżeli chcesz np. Pomyśleć o dodatkowych aktywnościach integracyjnych, może dodać:
Jeżeli rezultat będzie OK, idziemy dalej:
Na koniec, wisienką na torcie — rezultat (tabelę lub wyeksportowany z Czata dokument) wklejasz do kolejnego promptu, i dodajesz:
🤯🤯🤯
Bardzo polecam, abyś planując kolejne wydarzenie, spotkanie czy seminarium spróbował/a zastosować ten schemat. I będę super wdzięczny, jeśli dasz znać, jak poszło 😊.
Być może widziałaś/eś śmieszne memy, pokazujące, jak kiepsko te (mające zabrać nam pracę) LLM-y radzą sobie z matematyką ;). Wynika to oczywiście z fundamentalnych założeń leżących u podstaw modeli i rzeczywiście, bez odpowiednich narzędzi dostępnych dla modelu, mogą być wyzwaniem.
Technika Chain-of-Thought bywa w takich przypadkach pomocna i pomaga dojść do właściwego rezultatu. Może być również użyta wszędzie tam, gdzie duże znaczenie ma logika (np. łamigłówki, problemy, etc..). CoT wymaga bardzo niewiele pracy — wystarczy dodać w promptcie wymaganie, aby LLM opisał dokładnie każdy krok procesu, dążąc do zadanego rezultatu. W praktyce może to być tak absurdalnie proste, jak dodanie `“przeanalizuj to, krok po kroku”` o zapytania.
Brzmi super zaawansowanie? 😂 w rzeczywistości ultra prosta koncepcja:
W praktyce — jak może wyglądać One-Shot?
Kiedy to się przydaje? Jest super ważne w przypadku tworzenia agentów AI, jeżeli spodziewamy się odpowiedzi np. W formacie JSON, i potrzebujemy konkretne atrybuty (konkretnych typów) w odpowiedzi. Osobiście nie stosuję One-Shot ani Multi-Shot nigdzie poza właśnie automatyzacjami.
Na koniec, jeszcze jedna bardzo przydatna technika. Zwłaszcza w pracach koncepcyjnych, strategii, planowaniu itp.. Chodzi o zrobienie kroku wstecz względem swojego pierwszego zapytania. To pozwala LLM-owi “aktywować” właściwe obszary wiedzy i uwzględniać je w późniejszych odpowiedziach. Rozumiejąc szerszy kontekst, LLM może generować bardziej trafne i prawidłowe odpowiedzi.
Z odpowiedzią może być różnie — w zależności od tego, gdzie zaprowadzi nas statystyka, możemy trafić na średnio przydatne pomysły. Spróbujmy zatem zrobić krok wstecz:
Teraz dajemy to podsumowanie w kolejnym promptcie i dodajemy:
Powiem krótko — sprawdziłem, działa 😎.
OK wyszło tego sporo. Znacznie więcej niż planowałem 😄. Mam nadzieję, że uda Ci się to wykorzystać. Gwarantuję, że jeśli choć kilka technik się u Ciebie “przyklei”, i zaczniesz z nich aktywnie korzystać, będziesz w top 10% użytkowników AI.
Wiem, że część z Was pracuje na MacOS (sam, być może niedługo, dołączę do tego grona), ale dla pozostałych, którzy pracują na Windowsie, mam mega przydatną wskazówkę. Jeżeli jeszcze nie korzystasz — zainstaluj sobie Microsoft PowerToys.
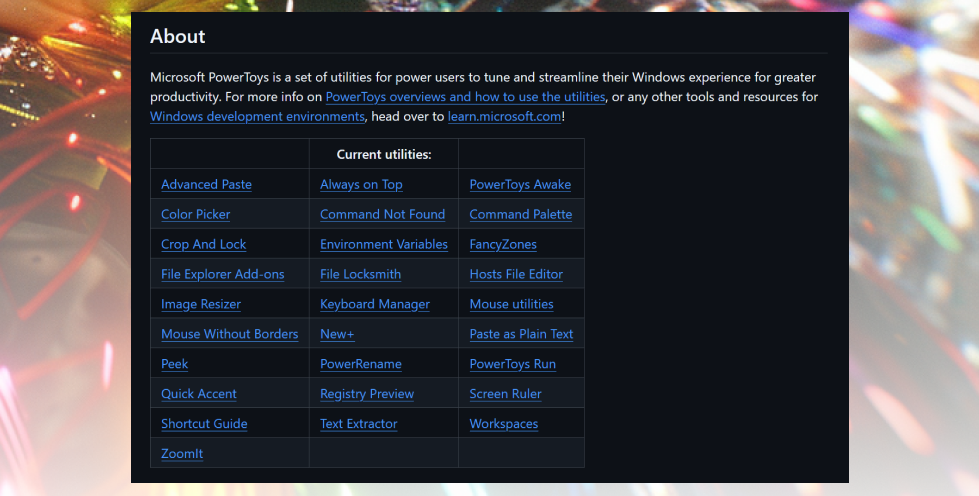
To zestaw dodatkowych funkcjonalności, które niesamowicie podnoszą produktywność i zastępują masę dodatkowych narzędzi i programików. W PowerToys znajdziesz, między innymi:
W całym zestawie znajdziesz blisko 30 narzędzi i usprawnień — część z nich dla bardziej technicznych użytkowników, ale większość przyda się każdemu profesjonaliście, który chce usprawnić i przyśpieszyć swoją pracę z Windowsem.
Trochę z innej beczki — sprawdź workout.cool. To platforma do monitorowania treningów, na licencji open-source. Możesz korzystać z konta na stronie, możesz natomiast wejść na GitHuba, pobrać kod źródłowy, i uruchomić workout.cool na swoim własnym sprzęcie — nie płacąc licencji i nie tracąc kontroli nad danymi.
Jeśli działasz w branży fitness — to może być także super platforma do wdrożenia dla monitorowania postępu Twoich podopiecznych.
Wracamy do Google. Jak być może wiesz, flagowy LLM Google to Gemini. Obecnie topowym modelem Gemini jest 2.5 Gemini Pro….
Z zupełnie niezwiązanych newsów — Google wypuściło, 4 dni temu Gemini CLI — czyli dostęp do modeli Gemini za pośrednictwem Command Line Interface, tak zwanego terminala. I wiem, nie jest to środowisko dla każdego, ale jeżeli masz chociaż trochę wprawy w terminalu, to warto spróbować. Przede wszystkim dlatego, że wraz z Gemini CLI (które jest, na marginesie, open-source) dostajesz też darmowy (no, musisz mieć konto Google) dostęp do bardzo zacnej ilości konwersacji z Gemini 2.5 Pro.
Jeżeli jeszcze nie korzystasz z płatnych modeli albo jesteś wciąż “tylko na” ChatGPT — zdecydowanie warto spróbować. A może, przy okazji, przekonasz się do terminala?

Dzisiaj wracam do Ciebie z książką, którą kilka lat temu polecił mi Tata. Czarny łabędź. Jak nieprzewidywalne zdarzenia rządzą naszym życiem, to bestsellerowa książka o nieprzewidywalności, autorstwa Nassima Nicolasa Taleba.
Taleb pokazuje, że największy wpływ na rzeczywistość mają zjawiska rzadkie, zaskakujące i nieprzewidywalne – czyli tytułowe „czarne łabędzie”. Dopiero po fakcie próbujemy je tłumaczyć, tworząc złudzenie, że „to było do przewidzenia”.
Książka stała się światowym bestsellerem, weszła do kanonu współczesnego myślenia o ryzyku i niepewności – jest cytowana przez inwestorów, przedsiębiorców, ekonomistów i filozofów. Dla wielu była „mind openerem”, który zmienił sposób postrzegania świata – zwłaszcza po kryzysie 2008.
Jest to mieszanka anegdot, filozofii, statystyki i zgryźliwych uwag autora pod adresem akademików, dziennikarzy i ekspertów. Taleb nie jest łatwy w odbiorze (ma równie spore grono fanów, jak i krytyków) – bywa zarozumiały i prowokacyjny – ale właśnie to sprawia, że Czarny Łabędź zostaje w głowie na długo. Nawet jeśli z częścią tez się nie zgodzisz, zmuszą Cię one do myślenia.
Dlaczego warto przeczytać:
Sam przesłuchałem „The Black Swan”, standardowo — w wersji audio, w języku angielskim, jakieś 3 razy. Do pozostałych publikacji Taleba, jak chociażby „Antifragile”, czy „Skin in the game” pewnie wrócę w kolejnych odcinkach 😉.
Czytasz właśnie piąty odcinek newslettera Ogarniam Technologie. Przede mną wciąż masa zadań do zrobienia, aby newsletter rósł, a każda edycja dawała Wam maksymalną wartość. Z rzeczy, których jeszcze nie ogarnąłem, wspomnę chociażby o:
Od ostatniego tygodnia nie wprowadziłem znaczących usprawnień, poza poprawieniem kilku drobnych błędów na stronie (dziękuję za feedback), i dalszej automatyzacji procesu przenoszenia treści newslettera z dokumentu Google Docs do gotowego szablonu wiadomości w formacie .html (dla MailerLite).
Piąta edycja newslettera dotrze do ok. 520 osób. Dziękuję, że jesteś wśród nich i dalej czytasz 🙏. Zgodnie z tradycją, zapraszam Cię także do podzielenia się swoimi uwagami dotyczącymi tej edycji newslettera. Każdy mail, który dostaję, to dodatkowa motywacja i energia do tworzenia coraz lepszych treści. Na każdy odpisuję i za każdy serdecznie dziękuję 🥰.
To wszystko na dziś, do usłyszenia w kolejnym tygodniu!
Pozdrawiam
Kuba Jaszczu

Zero spamu. Możesz wypisać się w każdej chwili.
Poznaj naszą politykę prywatności.